Amazon Bedrock – Integritätsschutz
Implementieren Sie Schutzmaßnahmen, die auf Ihre Anwendungsanforderungen und verantwortungsvollen KI-Richtlinien zugeschnitten sind.
Verantwortungsvolle KI-Anwendungen mit Integritätsschutz entwickeln
Amazon-Bedrock-Integritätsschutz bietet konfigurierbare Schutzmaßnahmen, um die sichere Entwicklung generativer KI-Anwendungen in großem Maßstab zu unterstützen. Dank eines konsistenten und standardisierten Ansatzes für verschiedenste Basismodelle, darunter von Amazon Bedrock unterstützte Basismodelle, optimierte Modelle und Modelle, die außerhalb von Amazon Bedrock gehostet werden, bietet der Integritätsschutz branchenführende Sicherheitsvorkehrungen:
- Nutzt Automated Reasoning, um sachliche Fehler aufgrund von Halluzinationen zu verhindern – die erste und einzige generative KI-Schutzmaßnahme, die das tut;
- Branchenführende Schutzmaßnahmen für Texte und Bilder, sodass Kunden bis zu 88 % der schädlichen multimodalen Inhalte blockieren können
- Filtert über 75 % halluzinierter Antworten aus Modellen für Anwendungsfälle wie Retrieval Augmented Generation (RAG) und Zusammenfassung.
Remitly Transforms Customer Support with Speed and Trust using Amazon Bedrock
KONE Powers Responsible AI Field Service with Amazon Bedrock
Ein einheitliches Maß an Sicherheit für Ihre generativen KI-Anwendungen
Integritätsschutz ist die einzige verantwortungsvolle KI-Funktion, die von einem großen Cloud-Anbieter angeboten wird und mit der Sie Sicherheits-, Datenschutz- und Wahrheitsschutzmaßnahmen für Ihre generativen KI-Anwendungen in einer einzigen Lösung erstellen und anpassen können. Integritätsschutz hilft bei der Bewertung von Benutzereingaben und modelliert Reaktionen auf der Grundlage von anwendungsfallspezifischen Richtlinien und bietet zusätzlich zu den von FMs standardmäßig bereitgestellten Sicherheitsvorkehrungen eine zusätzliche Sicherheitsebene. Integritätsschutz funktioniert mit einer Vielzahl von Modellen, darunter FMs, die in Amazon Bedrock unterstützt werden, optimierte Modelle und selbst gehostete Modelle außerhalb von Amazon Bedrock. Benutzereingaben und Modellausgaben können mithilfe der ApplyGuardrail-API unabhängig voneinander für Drittanbieter- und selbst gehostete Modelle ausgewertet werden. Integritätsschutz kann auch in Amazon-Bedrock-Agenten und Amazon-Bedrock-Wissensdatenbanken integriert werden, um sicherere generative KI-Anwendungen zu erstellen, die mit Richtlinien für verantwortungsvolle KI übereinstimmen.

Erkennen von Halluzinationen in Modellantworten mithilfe von kontextuellen Erdungstests
Kunden müssen wahrheitsgemäße und vertrauenswürdige generative KI-Anwendungen bereitstellen, um das Vertrauen der Nutzer zu bewahren und zu stärken. Allerdings können Basismodelle aufgrund von Halluzinationen falsche Informationen erzeugen: Sie weichen von den Quellinformationen ab, vermischen mehrere Informationen oder erfinden neue Informationen. Der Integritätsschutz unterstützt kontextbezogene Integritätsprüfungen, um Halluzinationen zu erkennen und zu filtern, wenn die Antworten nicht in den Quellinformationen begründet sind (beispielsweise sachlich falsche oder neue Informationen) und für die Anfrage oder Anweisung des Benutzers irrelevant sind. Kontextbezogene Integritätsprüfungen können dabei helfen, Halluzinationen für RAG-, Zusammenfassungs- und Konversationsanwendungen zu erkennen, bei denen die Quellinformationen als Referenz zur Validierung der Modellantwort verwendet werden können.

Sachliche Fehler aufgrund von Halluzinationen verhindern und überprüfbare Genauigkeit erreichen – mit Automated-Reasoning-Prüfungen
Automated-Reasoning-Prüfungen (Vorversion) im Amazon-Bedrock-Integritätsschutz sind die erste und einzige generative KI-Schutzmaßnahme, die dabei hilft, faktische Fehler durch Halluzinationen zu verhindern, indem sie logisch korrekte und überprüfbare Argumente liefert, die erklären, warum Antworten richtig sind. Automated Reasoning hilft, Halluzinationen abzuschwächen, indem fundierte mathematische Techniken verwendet werden, um die generierten Informationen zu verifizieren, zu korrigieren und logisch zu erklären. So wird sichergestellt, dass die Ergebnisse mit bekannten Fakten übereinstimmen und nicht auf erfundenen oder inkonsistenten Daten basieren. Entwickler können eine Automated-Reasoning-Richtlinie erstellen, indem sie ein vorhandenes Dokument hochladen, das den richtigen Lösungsbereich definiert, z. B. eine HR-Richtlinie oder ein Betriebshandbuch. Amazon Bedrock generiert dann eine einzigartige Automated-Reasoning-Richtlinie und führt die Benutzer durch das Testen und Verfeinern dieser Richtlinie. Zur Validierung der generierten Inhalte anhand einer Automated-Reasoning-Richtlinie müssen Benutzer die Richtlinie im Integritätsschutz aktivieren und sie mit einer Liste eindeutiger Amazon-Ressourcennamen (ARNs) konfigurieren. Dieser auf Logik basierende algorithmische Überprüfungsprozess stellt sicher, dass die von einem Modell generierten Informationen mit bekannten Fakten übereinstimmen und nicht auf fabrizierten oder inkonsistenten Daten basieren. Diese Prüfungen liefern nachweislich wahrheitsgetreue Antworten von generativen KI-Modellen und ermöglichen es Softwareanbietern, die Zuverlässigkeit ihrer Anwendungen für Anwendungsfälle in den Bereichen Personal, Finanzen, Recht, Compliance und mehr zu verbessern.

Unerwünschte Themen in generativen KI-Anwendungen blockieren
Unternehmensleiter erkennen die Notwendigkeit, Interaktionen innerhalb generativer KI-Anwendungen zu verwalten, um ein relevantes und sicheres Nutzererlebnis zu gewährleisten. Diese möchten die Interaktionen weiter anpassen, damit sie sich auf Themen konzentrieren, die für ihr Unternehmen relevant sind, und sich an den Unternehmensrichtlinien orientieren. Mithilfe einer kurzen Beschreibung in natürlicher Sprache hilft Ihnen der Integritätsschutz dabei, eine Reihe von Themen zu definieren, die im Kontext Ihrer Anwendung zu vermeiden sind. Integritätsschutz hilft bei der Erkennung und Blockierung von Benutzereingaben und FM-Antworten, die in die eingeschränkten Themen fallen. Beispielsweise kann ein Bankassistent so konzipiert werden, dass er Themen im Zusammenhang mit Anlageberatung vermeidet.

Filtern Sie schädliche multimodale Inhalte auf der Grundlage Ihrer Richtlinien für verantwortungsvolle KI
Integritätsschutz bietet Inhaltsfilter mit konfigurierbaren Schwellenwerten für toxische Text- und Bildinhalte. Der Schutz hilft bei der Filterung schädlicher multimodaler Inhalte, die u. a. Hassreden, Beleidigungen, Sex, Gewalt und Fehlverhalten (einschließlich krimineller Aktivitäten) enthalten, und trägt zum Schutz vor Prompt-Angriffen bei (Promptinjektion und Jailbreak). Mithilfe von Inhaltsfiltern werden die Benutzereingaben und die Antworten des Modells automatisch ausgewertet, um unerwünschte und potenziell schädliche Texte und/oder Bilder zu erkennen und zu verhindern. Beispielsweise kann eine E-Commerce-Website ihren Online-Assistenten so gestalten, dass unangemessene Ausdrücke wie Hassreden oder Beleidigungen vermieden werden.

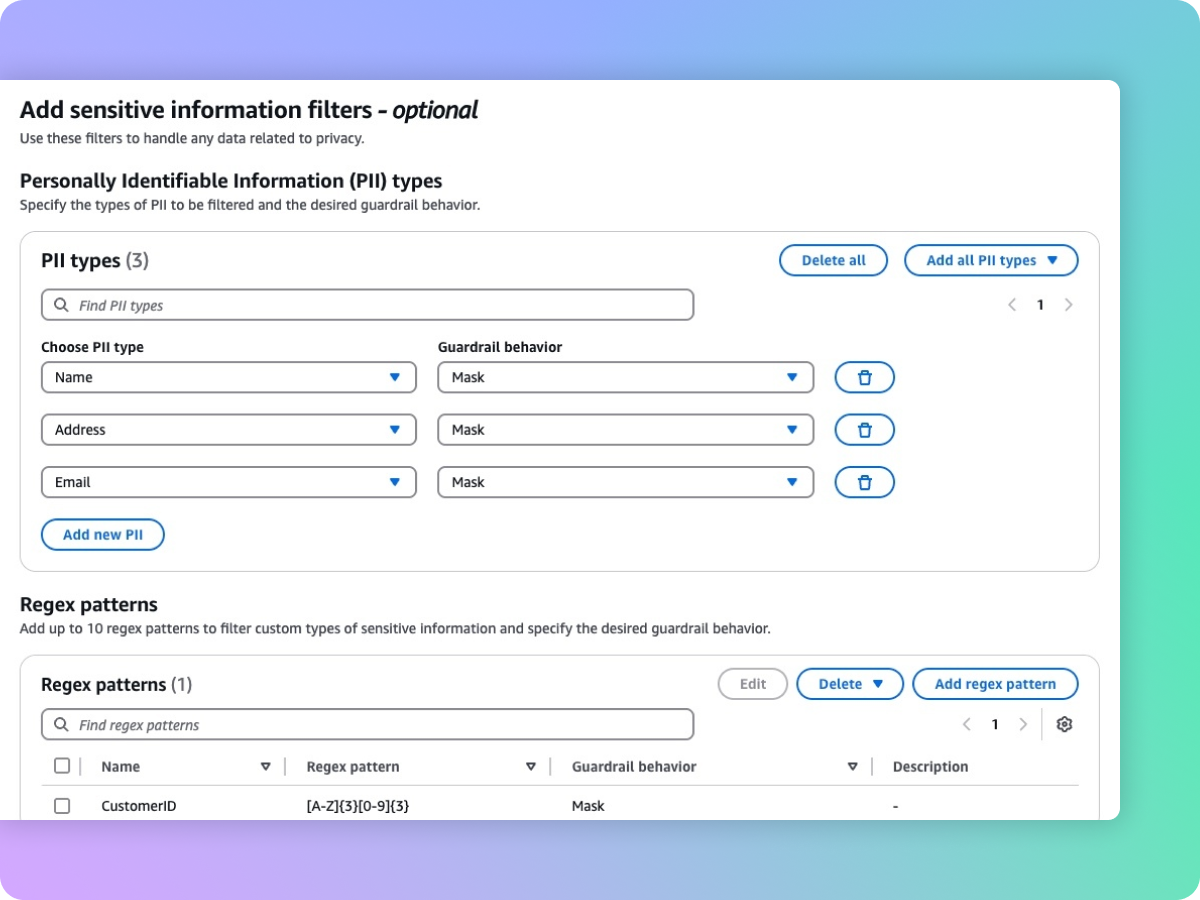
Vertrauliche Informationen wie PII zum Schutz der Privatsphäre zensieren
Integritätsschutz hilft Ihnen dabei, vertrauliche Inhalte wie persönlich identifizierbare Informationen (PII) in Benutzereingaben und FM-Antworten zu erkennen. Sie können aus einer Liste vordefinierter PII auswählen oder mithilfe regulärer Ausdrücke (RegEx) einen benutzerdefinierten Typ vertraulicher Informationen definieren. Je nach Anwendungsfall können Sie Eingaben, die vertrauliche Informationen enthalten, selektiv ablehnen oder sie in FM-Antworten zensieren. So können Sie z. B. in einem Callcenter die persönlichen Daten der Benutzer bei der Erstellung von Zusammenfassungen aus Gesprächsprotokollen von Kunden und Kundendienstmitarbeitern schwärzen.
Nächste Schritte
Haben Sie die gewünschten Informationen gefunden?
Ihr Beitrag hilft uns, die Qualität der Inhalte auf unseren Seiten zu verbessern.