- Analytique›
- Amazon EMR›
- Fonctionnalités
Fonctionnalités d’Amazon EMR
Facilité d'utilisation
Présentation
Amazon EMR simplifie la création et l'exploitation des environnements et applications Big Data. Les fonctionnalités d'EMR associées incluent le provisionnement, la mise à l'échelle gérée et la reconfiguration aisés des clusters et d'ERM Studio pour le développement collaboratif.
Mise en service des clusters en quelques minutes
Vous pouvez lancer un cluster EMR en quelques minutes. Vous n'avez pas à vous préoccuper du provisionnement de l'infrastructure, de l'installation, de la configuration ou de l'optimisation du cluster. EMR s’occupe de ces tâches et vous permet de concentrer vos équipes sur le développement d’applications Big Data différenciées.
Mise à l’échelle aisée des ressources aux besoins de l’entreprise
Vous pouvez facilement définir des politiques d’augmentation et de réduction horizontale à l’aide d’EMR Managed Scaling et laisser votre cluster EMR gérer automatiquement les ressources de calcul pour répondre à vos besoins en termes d’utilisation et de performances. Cela permet d'améliorer l'utilisation du cluster et de réduire les coûts.
EMR Studio
Il s’agit d’un environnement de développement intégré (IDE) qui permet aux scientifiques et ingénieurs des données de facilement développer, visualiser et déboguer les applications d’ingénierie et de science des données écrites en R, Python, Scala et PySpark. EMR Studio fournit des blocs-notes Jupyter entièrement gérés et des outils tels que Spark UI et YARN Timeline Service pour simplifier le débogage.
Haute disponibilité en un clic
Vous pouvez facilement configurer la haute disponibilité pour des applications multimaîtres telles que YARN, HDFS, Apache Spark, Apache HBase et Apache Hive d’un simple clic. Lorsque vous activez la prise en charge multimaître dans EMR, EMR configure ces applications pour la haute disponibilité et, en cas de défaillance, bascule automatiquement vers un maître en veille afin que votre cluster ne soit pas perturbé, et place vos nœuds principaux dans des racks distincts afin de réduire le risque de défaillance simultanée. Les hôtes sont surveillés pour détecter les échecs et, lorsque des problèmes sont découverts, de nouveaux hôtes sont mis en service et ajoutés automatiquement au cluster.
EMR Managed Scaling
Redimensionne automatiquement votre cluster pour des performances optimales au coût le plus bas possible. Avec Amazon EMR Managed Scaling, vous spécifiez les limites de calcul minimum et maximum pour vos clusters, et Amazon EMR les redimensionne automatiquement pour de meilleures performances et une utilisation des ressources optimisée. EMR Managed Scaling échantillonne continuellement les métriques clés associées aux charges de travail s'exécutant sur les clusters.
Reconfiguration aisée des clusters en cours d’exécution
Vous pouvez désormais modifier la configuration des applications exécutées sur des clusters EMR, y compris Apache Hadoop, Apache Spark, Apache Hive et Hue, et ce sans besoin de redémarrer le cluster. La reconfiguration des applications EMR permet de modifier les applications à la volée sans arrêter ou recréer le cluster. Amazon EMR applique vos nouvelles configurations et redémarre proprement l'application reconfigurée. Les configurations peuvent être appliquées via la console, le kit SDK ou l’interface de ligne de commande (CLI).
Élastique
Présentation
Amazon EMR vous permet de mettre facilement et rapidement en service la capacité dont vous avez besoin et d'ajouter ou de supprimer de la capacité de façon automatique ou manuelle. Cela s'avère utile si vos besoins en traitement sont variables ou imprévisibles. Par exemple, si la plus grande partie de votre traitement s'effectue pendant la nuit, il est possible que vous ayez besoin de 100 instances pendant la journée et de 500 instances pendant la nuit. Par ailleurs, vous pourriez également avoir besoin d'une capacité très importante sur une courte période. Avec Amazon EMR, vous pouvez rapidement mettre en service des centaines ou des milliers d'instances, les redimensionner automatiquement afin qu'elles s'adaptent à la configuration requise pour le calcul, et fermer votre cluster lorsque votre tâche est terminée (pour éviter le coût d'une capacité inactive).

Deux options principales sont disponibles pour ajouter ou supprimer de la capacité :
Déploiement de plusieurs clusters
Si vous avez besoin de davantage de capacité, vous pouvez facilement lancer un nouveau cluster et y mettre fin lorsque vous n’en avez plus besoin. Le nombre de clusters n'est pas limité. Il peut être judicieux d'utiliser plusieurs clusters lorsque vous avez plusieurs utilisateurs ou applications. Par exemple, vous pouvez stocker vos données d'entrée dans Amazon S3, puis lancer un cluster pour chaque application ayant besoin de traiter les données. Un cluster peut être optimisé pour le CPU, un second cluster peut être optimisé pour le stockage, etc.
Redimensionnement d’un cluster en cours d’exécution
Amazon EMR facilite l’utilisation d’EMR Managed Scaling, la mise à l’échelle automatique ou le redimensionnement manuel d’un cluster en cours d’exécution. Vous pouvez redimensionner un cluster de façon temporaire soit en l'agrandissant pour en augmenter la capacité de traitement, soit en diminuant sa taille pour réaliser des économies en cas d'inactivité. Par exemple, certains clients ajoutent des centaines d'instances à leurs clusters au moment du traitement par lots, puis suppriment les instances excédentaires lorsque le traitement est terminé. Lorsque vous ajoutez des instances à votre cluster, EMR peut désormais commencer à utiliser la capacité mise en service dès que celle-ci est disponible. Pendant le dimensionnement, EMR sélectionne de manière proactive les nœuds inutilisés pour réduire l'impact sur les tâches en cours d'exécution.
Faible coût
Présentation
Amazon EMR est conçu pour réduire le coût du traitement de quantités importantes de données. Parmi les fonctionnalités qui abaissent son coût figurent la tarification basse à la seconde, l'intégration des instances Spot Amazon EC2 et des instances réservées Amazon EC2, l'élasticité ainsi que l'intégration d'Amazon S3.
Faible tarification par seconde
La tarification d’Amazon EMR est calculée à la seconde, avec un forfait minimum d’une minute, et commence à 0,015 USD par heure d’instance pour une petite instance (131,40 USD par an). Pour en savoir plus, consultez la section relative à la tarification.
Intégration d’Amazon EC2 Spot
Le prix des instances Spot Amazon EC2 varie selon l’offre et la demande en instances, mais vous ne payez jamais plus que le prix que vous avez spécifié. Amazon EMR permet d’utiliser les instances Spot facilement et d’économiser ainsi du temps et de l’argent. Les clusters Amazon EMR comprennent des « nœuds principaux » qui exécutent HDFS et des « nœuds de tâches » qui ne l'exécutent pas. Les nœuds de tâches sont idéaux pour les instances Spot. En effet, si le prix des instances Spot augmente et que vous perdez ces instances, vous ne perdrez pas les données stockées dans HDFS. (En savoir plus à propos des nœuds principaux et des nœuds de tâches.) Grâce à la combinaison des flottes d’instances, des stratégies d’allocation pour les instances Spot, d’EMR Managed Scaling et d’autres options de diversification, vous pouvez désormais optimiser EMR en termes de résilience et de coût. Pour en savoir plus, consultez notre blog.
Intégration Amazon S3
Le système de fichiers EMR (EMRFS) permet aux clusters EMR d’utiliser Amazon S3 comme espace de stockage d’objets pour Hadoop, de façon efficace et en toute sécurité. Vous pouvez stocker vos données dans Amazon S3 et utiliser plusieurs clusters Amazon EMR pour traiter le même ensemble de données. Chaque cluster peut être optimisé pour une charge de travail particulière, ce qui peut être plus efficace que d'utiliser un seul cluster supportant plusieurs charges de travail avec des besoins différents. Par exemple, un cluster peut être optimisé pour les E/S et un autre pour le CPU, en traitant chacun les mêmes données dans Amazon S3. En outre, en stockant vos données d'entrée et de sortie dans Amazon S3, vous pouvez fermer des clusters lorsque vous n'en avez plus besoin.
Le système EMRFS offre des performances élevées en matière d’écriture vers et à partir d’Amazon S3, prend en charge le chiffrement S3 côté serveur ou côté client à l’aide d’AWS Key Management Service (KMS) ou de clés gérées par le client, et fournit une vue cohérente optionnelle, qui vérifie la liste et la cohérence read-after-write (lecture directe après écriture) des objets suivis dans ses métadonnées. De plus, les clusters EMR peuvent utiliser aussi bien le système EMRFS que le système HDFS ; vous n'avez donc pas à choisir entre un stockage sur le cluster et Amazon S3.
Intégration au catalogue de données AWS Glue
Vous pouvez utiliser le catalogue de données AWS Glue en tant que référentiel de métadonnées géré pour conserver les métadonnées des tables externes pour Apache Spark et Apache Hive. De plus, il apporte une découverte ainsi qu'un historique des versions des schémas automatique. Cela vous permet de conserver facilement les métadonnées de vos tableaux externes sur Amazon S3 en dehors de votre cluster.
Des magasins de données flexibles
Présentation
Avec Amazon EMR, vous pouvez utiliser plusieurs magasins de données, y compris Amazon S3, le système de fichiers distribués Hadoop (HDFS) et AmazonDynamoDB.
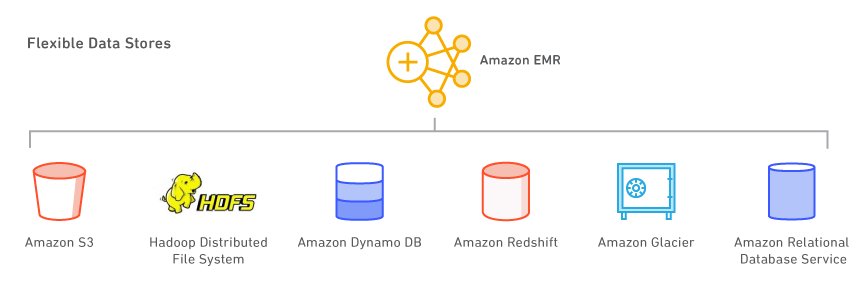
Amazon S3
Amazon S3 est un service de stockage hautement durable, évolutif, sécurisé, rapide et économique. Grâce au système de fichiers EMR (EMRFS), Amazon EMR peut utiliser Amazon S3 comme un espace de stockage d’objets pour Hadoop, de façon efficace et sécurisée. Amazon EMR a apporté de nombreuses améliorations à Hadoop, ce qui vous permet de traiter avec fluidité de grandes quantités de données stockées dans Amazon S3. De plus, le système EMRFS peut activer la vue cohérente afin de vérifier la liste et la cohérence read-after-write des objets dans Amazon S3. Le système EMRFS prend en charge le chiffrement S3 côté serveur ou côté client pour traiter les objets Amazon S3 chiffrés, et vous pouvez utiliser AWS Key Management Service (KMS) ou un fournisseur de clés personnalisées.
Lorsque vous lancez un cluster, Amazon EMR diffuse les données d'Amazon S3 vers chaque instance du cluster et commence à les traiter immédiatement. L'avantage lié au stockage de vos données dans Amazon S3 et à leur traitement par Amazon EMR réside dans le fait que vous pouvez utiliser plusieurs clusters pour traiter les mêmes données. Par exemple, vous pouvez posséder un cluster de développement Hive, optimisé pour la mémoire, et un cluster de production Pig, optimisé pour la CPU, qui utilisent tous deux le même ensemble de données d'entrée.
Système de fichiers distribué Hadoop (HDFS)
HDFS est le système de fichiers Hadoop. La topologie actuelle d'Amazon EMR divise ses instances dans 3 groupes d'instances logiques : le groupe maître, qui exécute le gestionnaire de ressources YARN et le service de Name Node HDFS ; le groupe de cœur, qui exécute le démon DataNode HDFS et le service de gestionnaire de nœud YARN ; enfin, le groupe de tâche, qui exécute le service de gestionnaire de nœud YARN. Amazon EMR installe HDFS sur l'espace de stockage associé aux instances dans le groupe de cœur.
Chaque instance EC2 est fournie avec une capacité de stockage fixe, appelée « stockage d'instance » et rattachée à l'instance. Vous pouvez également modifier la capacité de stockage d’une instance donnée en y ajoutant des volumes Amazon EBS. Amazon EMR vous permet d’ajouter des types de volumes à usage général (SSD), provisionnés (SSD) et magnétiques. Les volumes EBS ajoutés à un cluster EMR ne conservent pas les données après l'arrêt du cluster. EMR effacera automatiquement les volumes une fois le cluster supprimé.
Vous pouvez également activer le chiffrement intégral pour HDFS à l’aide d’une configuration de sécurité Amazon EMR ou créer manuellement des zones de chiffrement HDFS avec le serveur de gestion de clés Hadoop. Vous pouvez utiliser une option de configuration de sécurité pour chiffrer le périphérique racine et les volumes de stockage EBS lorsque vous spécifiez AWS KMS comme votre fournisseur de clés. Pour plus d’informations, consultez la section Local Disk Encryption.
Amazon DynamoDB
Amazon DynamoDB est un service rapide et entièrement géré de bases de données NoSQL. Amazon EMR dispose d’une intégration directe avec Amazon DynamoDB, ce qui vous permet de traiter rapidement et efficacement les données stockées dans Amazon DynamoDB et de transférer des données entre Amazon DynamoDB, Amazon S3 et HDFS, dans Amazon EMR.
Autres magasins de données AWS
Vous pouvez également utiliser Amazon Relational Database Service (un service Web qui facilite la configuration, l’exploitation et la mise à l’échelle des bases de données relationnelles dans le cloud), Amazon Glacier (un service de stockage à coût extrêmement faible, qui fournit un stockage sécurisé et durable pour l’archivage et la sauvegarde de données) et Amazon Redshift (un service d’entrepôt de données rapide et totalement géré, d’une capacité de plusieurs pétaoctets). AWS Data Pipeline est un service Web qui vous aide à traiter et à transférer des données de manière fiable entre différents services AWS de stockage et de calcul (notamment Amazon EMR), ainsi que des sources de données sur site, selon des intervalles définis.
Utiliser vos applications open source préférées
Présentation
Grâce au contrôle de version sur Amazon EMR, vous pouvez facilement sélectionner et utiliser les derniers projets open source dans votre cluster EMR, notamment des applications dans les écosystèmes Apache Spark et Hadoop. Le logiciel est installé et configuré par Amazon EMR. Vous pouvez donc consacrer plus de temps à la valorisation de vos données sans vous soucier des tâches d'infrastructure et d'administration.

Outils Big Data
Présentation
Amazon EMR prend en charge de puissants outils Hadoop à l'efficacité prouvée tels qu'Apache Spark, Apache Hive, Presto et Apache HBase. Les spécialistes des données, utilisent EMR pour exécuter les outils de deep learning et de machine learning, tels que TensorFlow, Apache MXNet et, en utilisant des actions d'amorçage, ajoutent des outils et bibliothèques spécifiques à chaque cas d'utilisation. Les analystes des données utilisent EMR Studio, Hue et EMR Notebooks pour le développement interactif, la création de tâches Apache Spark et soumettre des requêtes SQL à Apache Hive et à Presto. Les ingénieurs de données utilisent EMR pour le développement de pipeline de données et le traitement de données, et Apache Hudi pour simplifier les cas d'utilisation liés à la gestion des données incrémentielles et à la confidentialité des données nécessitant des opérations d'insertion, de mise à jour et de suppression au niveau de l'enregistrement.

Traitement des données et machine learning
Apache Spark est un moteur de l’écosystème Hadoop qui traite rapidement de grands jeux de données. Il utilise des ensembles de données RDD (Resilient Distributed Datasets) tolérants aux pannes et des graphiques DAG (Directed, Acyclic Graph) pour définir les transformations de données. Spark comprend également Spark SQL, Spark Streaming, MLlib et GraphX. Découvrez Spark et apprenez-en davantage sur Spark sur EMR.
Apache Flink est un moteur de flux de données de diffusion qui facilite l’exécution du traitement de flux en temps réel sur des sources de données à haut débit. Il prend en charge la sémantique d'heure d'événement pour les événements hors d'ordre, la sémantique unique, le contrôle de contre-pression et les API optimisées pour l'écriture d'applications de diffusion et en mode batch. Découvrez Flink et apprenez-en davantage sur Flink sur EMR.
TensorFlow est une bibliothèque mathématique symbolique open source pour l’intelligence artificielle et les applications de deep learning. TensorFlow regroupe plusieurs modèles et algorithmes de machine learning et de deep learning et peut former et exploiter des réseaux neuronaux profonds pour de nombreux cas d'utilisation. En savoir plus sur TensorFlow sur EMR.
Gestion des données au niveau de l'enregistrement dans Amazon S3
Apache Hudi est un framework de gestion des données open source utilisé pour simplifier le traitement des données incrémentielles et le développement de pipelines de données. Apache Hudi vous permet de gérer les données au niveau de l'enregistrement dans Amazon S3 afin de simplifier la capture des données modifiées (CDC) et la transmission en continu des données. Il fournit également un framework permettant de gérer les cas d'utilisation de la confidentialité des données nécessitant des mises à jour et suppressions au niveau de l'enregistrement. En savoir plus sur Apache Hudi sur Amazon EMR.
SQL
Apache Hive est un entrepôt des données open source et un package analytique qui s’exécute sur Hadoop. Hive est exploité par Hive QL, un langage basé sur SQL qui permet aux utilisateurs de structurer, de récapituler et d'interroger des données. Hive QL va au-delà du SQL standard, en ajoutant une assistance de première catégorie en ce qui concerne les fonctions MapReduce et les types de données complexes extensibles définies par l'utilisateur comme Json et Thrift. Cette capacité permet le traitement de sources de données complexes et même non structurées comme les documents textes et les fichiers journaux. Hive permet d'utiliser des extensions utilisateur, grâce aux fonctions définies par l'utilisateur écrites dans Java. Amazon EMR a apporté de nombreuses améliorations à Hive, notamment l'intégration directe avec Amazon DynamoDB et Amazon S3. Par exemple, avec Amazon EMR, vous pouvez charger automatiquement des partitions de table depuis Amazon S3, écrire des données dans des tables dans Amazon S3 sans utiliser des fichiers temporaires, et accéder à des ressources dans Amazon S3, telles que des scripts pour des opérations de mappage/réduction personnalisées et des bibliothèques supplémentaires. Découvrez Hive et apprenez-en davantage sur Hive sur EMR.
Presto est un moteur de requêtes SQL distribué open source optimisé pour l’analyse ad hoc des données avec un faible temps de latence. Il prend en charge la norme ANSI SQL, y compris les requêtes complexes, les agrégations, les jonctions et les fonctions de fenêtrage. Presto peut traiter des données provenant de plusieurs sources, notamment le système de fichiers distribués Hadoop (HDFS, Hadoop Distributed File System) et Amazon S3. Découvrez Presto et apprenez-en davantage sur Presto sur EMR.
Apache Phoenix permet de profiter de SQL à faible latence avec des capacités de transaction ACID sur les données stockées dans Apache HBase. Vous pouvez facilement créer des index secondaires pour améliorer les performances et créer des vues différentes sur la même table HBase sous-jacente. En savoir plus sur Phoenix sur EMR.
NoSQL
Apache HBase est une base de données à code source ouvert, non relationnelle et distribuée, conçue sur le modèle de BigTable de Google. Elle a été développée dans le cadre du projet Apache Sofware Foundation de Hadoop et elle s'exécute au-dessus du système de fichiers distribués HDFS (Hadoop Distributed File System) afin de lui fournir des capacités comparables à celles de BigTable. HBase offre un stockage tolérant aux pannes et efficace de volumes importants de données dispersées, qui utilise la compression et le stockage basés sur des colonnes. De plus, HBase permet de chercher rapidement des données grâce à sa fonction de mise en cache en mémoire. Il est optimisé pour les opérations d'écriture séquentielle et très efficace pour l'insertion, la mise à jour et la suppression de lots. Il fonctionne de manière fluide avec Hadoop en partageant son système de fichiers et en servant d'entrée et de sortie directe pour les tâches dans Hadoop. Il intègre également Apache Hive, ce qui permet les requêtes de type SQL sur les tables HBase, se joint aux tables basées sur Hive et permet la prise en charge de la connectivité des bases de données Java (JDBC). Avec EMR, vous pouvez utiliser S3 comme magasin de données pour HBase afin de limiter les coûts et de réduire la complexité opérationnelle. Si vous utilisez HDFS comme magasin de données, vous pouvez sauvegarder HBase sur S3 et exécuter une restauration à partir d'une sauvegarde précédemment créée. Découvrez HBase et apprenez-en davantage sur HBase sur EMR.
Analyse interactive
EMR Studio est un environnement de développement intégré (IDE) qui permet aux scientifiques et ingénieurs des données de facilement développer, visualiser et déboguer les applications d’ingénierie et de science des données écrites en R, Python, Scala et PySpark. EMR Studio fournit des blocs-notes Jupyter entièrement gérés et des outils tels que Spark UI et YARN Timeline Service pour simplifier le débogage.
Hue est une interface utilisateur open source pour Hadoop qui facilite l’exécution et le développement de requêtes Hive, la gestion de fichiers dans HDFS, l’exécution et le développement de scripts Pig et la gestion de tables. Hue on EMR s'intègre également à Amazon S3. Par conséquent, vous pouvez interroger directement S3 et transférer facilement des fichiers entre HDFS et Amazon S3. En savoir plus sur Hue et EMR.
Les blocs-notes Jupyter consistent en une application Web open source que vous pouvez utiliser pour créer et partager des documents contenant du code en direct, des équations, des visualisations et du texte narratif. JupyterHub vous permet d'héberger plusieurs instances d'un serveur de blocs-notes Jupyter mono-utilisateurs. Lorsque vous créez un cluster EMR avec JupyterHub, EMR crée un conteneur Docker sur le nœud principal du cluster. JupyterHub, tous les composants requis pour Jupyter et Sparkmagic s’exécutent dans le conteneur.
Apache Zeppelin est une interface graphique open source qui crée des blocs-notes interactifs et collaboratifs pour l’exploration des données en utilisant Spark. Vous pouvez utiliser Scala, Python, SQL (à l'aide de Spark SQL) ou HiveQL pour manipuler les données et visualiser rapidement les résultats. Les blocs-notes Zeppelin peuvent être partagés entre plusieurs utilisateurs et les visualisations peuvent être publiées sur des tableaux de bord externes. En savoir plus sur Zeppelin sur EMR.
Planification et flux de travail
Apache Oozie est un planificateur de flux de travail pour Hadoop dans lequel vous pouvez créer des graphes orientés acycliques (DAG) d’actions. Vous pouvez également déclencher vos flux de travail Hadoop en fonction des actions ou de l'heure. En savoir plus sur Oozie sur EMR. AWS Step Functions vous permet d'ajouter une automatisation de flux de travail sans serveur à vos applications. Les étapes de votre flux de travail peuvent s'exécuter n'importe où, y compris dans les fonctions AWS Lambda, sur Amazon Elastic Compute Cloud (EC2) ou sur site. En savoir plus sur Step Functions sur EMR.
Autres projets et outils
EMR prend également en charge plusieurs autres applications et outils courants, tels que R, Apache Pig (traitement de données et ETL), Apache Tez (exécution de DAG complexe), Apache MXNet (deep learning), Ganglia (surveillance), Apache Sqoop (connecteur de base de données relationnelle), HCatalog (gestion des tables et du stockage), etc. L’équipe Amazon EMR gère un référentiel open source d’actions d’amorçage pouvant être utilisées pour installer un logiciel supplémentaire, configurer votre cluster ou servir d’exemple pour l’écriture de vos propres actions d’amorçage.
Contrôle d'accès aux données
Présentation
Par défaut, les processus d’application Amazon EMR utilisent le profil d’instance EC2 lorsqu’ils appellent d’autres services AWS. Pour les clusters à locataires multiples, Amazon EMR offre trois options afin de gérer l'accès des utilisateurs aux données Amazon S3.
L’intégration avec AWS Lake Formation vous permet de définir et de gérer des stratégies d’autorisation précises dans AWS Lake Formation pour accéder aux bases de données, tableaux et colonnes du catalogue de données AWS Glue. Vous pouvez appliquer les stratégies d’autorisation aux tâches soumises via les Blocs-notes Amazon EMR et Apache Zeppelin pour les charges de travail EMR Spark interactives, et envoyer les événements d’audit à AWS CloudTrail. En permettant cette intégration, vous permettez également une authentification unique fédérée pour EMR Notebooks ou Apache Zeppelin à partir de systèmes d'identité d'entreprise compatibles avec Security Assertion Markup Language (SAML) 2.0.
Grâce à l’intégration native avec Apache Ranger, vous pouvez configurer un nouveau serveur ou un serveur existant Apache Ranger afin de définir et de gérer des stratégies d’autorisation précises permettant aux utilisateurs d’accéder aux bases de données, tables et colonnes de données Amazon S3 via Hive Metastore. Apache Ranger est un outil open source qui active, surveille et gère la sécurité exhaustive des données sur la plateforme Hadoop.
Cette intégration native vous permet de définir trois types de stratégies d’autorisation sur le serveur Policy Admin Apache Ranger. Vous pouvez configurer des autorisations au niveau des lignes, colonnes et tables pour Hive, au niveau des colonnes et des tables pour Spark, et au niveau des objets et des préfixes pour Amazon S3. Amazon EMR installe et configure automatiquement les modules d'extension Apache Ranger correspondants sur le cluster. Ces modules d’extension Ranger se synchronisent avec le serveur Policy Admin pour les stratégies d’autorisation, appliquent des contrôles d’accès aux données et envoient des événements d’audit à Amazon CloudWatch Logs.
Amazon EMR User Role Mapper vous permet d’exploiter les autorisations AWS IAM pour gérer les accès aux ressources AWS. Vous pouvez créer des mappages entre les utilisateurs (ou groupes) et personnaliser les rôles IAM. Un utilisateur ou un groupe ne peut accéder qu'aux données autorisées par le rôle IAM personnalisé. Cette fonctionnalité est actuellement disponible via AWS Labs.
Expérience hybride cohérente
Présentation
AWS Outposts est un service entièrement géré qui permet d’exploiter l’infrastructure, les services, les API et les outils AWS avec la quasi-totalité des centres de données, espaces d’hébergement ou installations sur site. Amazon EMR sur AWS Outposts permet de déployer et de gérer des clusters EMR dans votre centre de données avec la même console de gestion AWS, le même kit de développement logiciel (SDK) et la même interface de ligne de commande (CLI) que pour EMR.
Fonctionnalités supplémentaires
Sélection de l’instance adaptée à votre cluster
Vous choisissez les types d’instances EC2 à mettre en service dans votre cluster (standard, mémoire élevée, CPU élevée, E/S élevées, etc.) en fonction des exigences de votre application. Vous disposez d'un accès racine à chaque instance et vous pouvez entièrement personnaliser votre cluster pour répondre à vos besoins. En savoir plus à propos des types d'instances Amazon EC2 pris en charge. Amazon EMR offre désormais un coût jusqu'à 30 % inférieur et des performances jusqu'à 15 % supérieures pour les charges de travail Spark sur les instances Graviton2. Pour en savoir plus, consultez notre blog.
Contrôle de l’accès réseau à votre cluster
Vous pouvez lancer votre cluster dans un Amazon Virtual Private Cloud (VPC), une section logiquement isolée du cloud AWS. Vous conservez la totale maîtrise de votre environnement réseau virtuel, y compris pour la sélection de votre propre plage d'adresses IP, la création de sous-réseaux et la configuration de tables de routage et de passerelles réseau. En savoir plus à propos d'Amazon EMR et d'Amazon VPC.
Débogage de vos applications
Lorsque vous activez le débogage dans un cluster, Amazon EMR archive les fichiers journaux dans Amazon S3, puis les indexe. Vous pouvez alors utiliser une interface graphique dans la console pour parcourir les journaux et consulter l'historique de tâches de manière intuitive. En savoir plus à propos des tâches de débogage Amazon EMR.
Gestion des utilisateurs, des autorisations et du chiffrement
Vous pouvez utiliser les outils d’AWS Identity and Access Management (IAM), tels que les utilisateurs et les rôles IAM, pour contrôler les accès et les autorisations. Par exemple, vous pouvez autoriser un accès à vos clusters en lecture seule à certains utilisateurs, mais pas d'accès en écriture. Vous pouvez également utiliser les configurations de sécurité Amazon EMR pour définir différentes options de chiffrement au repos et en transit, notamment la prise en charge du chiffrement Amazon S3 et l’authentification Kerberos. En savoir plus à propos du contrôle de l’accès à votre cluster et des options de chiffrement d’Amazon EMR.
Surveillez votre cluster
Vous pouvez utiliser Amazon CloudWatch pour surveiller des métriques personnalisées dans Amazon EMR, telles que le nombre tâches de traitement (« map ») et d’agrégation (« reduce »). Vous pouvez également définir des alarmes pour ces métriques. En savoir plus à propos de la surveillance des clusters Amazon EMR.
Installation de logiciels supplémentaires
Vous pouvez utiliser des actions d’amorçage ou une Amazon Machine Image (AMI) personnalisée exécutant Amazon Linux pour installer d’autres logiciels sur votre cluster. Les actions de démarrage sont des scripts qui sont exécutés sur les nœuds du cluster lorsque ce dernier est lancé par AmazonEMR. Ils s'exécutent avant le démarrage de Hadoop et avant que le nœud commence à traiter des données. Vous pouvez également précharger et utiliser des logiciels sur une AMI Amazon Linux personnalisée. En savoir plus à propos des actions d’amorçage Amazon EMR et des AMI Amazon Linux personnalisées.
Réponse aux événements
Vous pouvez utiliser les types d’événements Amazon EMR dans Amazon CloudWatch Events pour répondre aux changements d’état dans vos clusters Amazon EMR. À l’aide de simples règles configurables rapidement, vous pouvez faire correspondre les événements et les acheminer vers des sujets Amazon SNS, des fonctions AWS Lambda, des files d’attente Amazon SQS et bien plus encore. En savoir plus à propos des événements sur les clusters Amazon EMR.
Copie efficace des données
Vous pouvez rapidement déplacer des volumes importants de données d’Amazon S3 vers HDFS, de HDFS vers Amazon S3 et entre les compartiments d’Amazon S3 à l’aide de l’extension open source de l’outil Distcp appelé S3DistCp d’Amazon EMR, qui utilise MapReduce pour déplacer d’importants volumes de données. En savoir plus sur S3DistCp.
Planification des flux de travail récurrents
Vous pouvez utiliser AWS Data Pipeline pour programmer des flux de travail récurrents avec Amazon EMR. AWS Data Pipeline est un service Web qui vous permet de traiter et de transférer des données de manière fiable entre différents services AWS de stockage et de calcul, et vos sources de données sur site, selon des intervalles définis. En savoir plus à propos d'Amazon EMR et d'AWS Data Pipeline.
JAR personnalisé
Écrivez un programme Java, compilez-le avec la version de Hadoop que vous souhaitez utiliser, puis transférez-le dans Amazon S3. Vous pouvez ensuite envoyer des tâches Hadoop au cluster via l'interface Hadoop JobClient. En savoir plus à propos du traitement JAR personnalisé avec Amazon EMR.
Deep learning
Utilisez des cadres de deep learning courants comme Apache MXNet pour définir, entraîner et déployer des réseaux neuraux profonds. Vous pouvez utiliser ces frameworks sur des clusters Amazon EMR avec des instances GPU. En savoir plus sur MXNet sur Amazon EMR.