Amazon Bedrock のガードレール
アプリケーション要件と責任ある AI ポリシーに合わせてカスタマイズされた保護手段を実装する
ガードレールで責任ある AI アプリケーションを構築
Amazon Bedrock ガードレールには、生成 AI アプリケーションを大規模に安全に構築するのに役立つ設定可能な保護手段が用意されています。Amazon Bedrock でサポートされる基盤モデル (FM) を含めたさまざまな FM、ファインチューニングされたモデル、Amazon Bedrock 外でホストされるモデルの全体で使用される一貫した標準アプローチを活用するガードレールは、業界をリードする安全保護機能を提供します。
- 自動推論は、ハルシネーションによる事実の誤りを防止するのに役立ちます – これを実現する最初で唯一の生成 AI 保護手段です
- 業界をリードするテキストおよび画像コンテンツのセーフガードにより、お客様が最大 88% の有害マルチモーダルコンテンツをブロックできるように支援
- 検索拡張生成 (RAG) および要約のユースケース向けに、モデルからの 75% を超えるハルシネーション応答をフィルタリング
Remitly Transforms Customer Support with Speed and Trust using Amazon Bedrock
KONE Powers Responsible AI Field Service with Amazon Bedrock
生成 AI アプリケーション全体で一貫したレベルの安全性を実現
ガードレールは、大手クラウドプロバイダーが提供する唯一の責任ある AI 機能です。これは、生成 AI アプリケーションの安全性、プライバシー、信頼性の保護手段を 1 つのソリューション内で構築およびカスタマイズするのに役立ちます。ガードレールは、ユースケース固有のポリシーに基づいてユーザー入力とモデル応答を評価するのに役立ち、FM がネイティブに提供するものに加えて追加の保護手段を提供します。ガードレールは、Amazon Bedrock でサポートされる FM、ファインチューニングされたモデル、Amazon Bedrock の外部でセルフホストされるモデルなど、幅広いモデルで動作します。 ユーザー入力とモデル出力は、ApplyGuardRail API を使用してサードパーティーモデルとセルフホストモデルで個別に評価できます。 ガードレールは、責任ある AI ポリシーに適合するより安全な生成 AI アプリケーションを構築するために、Amazon Bedrock のエージェントやナレッジベースと統合することも可能です。

コンテキストを踏まえたグラウンディングチェックを使用して、モデル応答におけるハルシネーションを検出
顧客は、ユーザーの信頼を維持し、高めるために、真実で信頼できる生成 AI アプリケーションをデプロイする必要があります。ただし、FM は、ハルシネーションによって誤った情報を生成する可能性があります。つまり、ソース情報から逸脱したり、複数の情報を混同したり、新しい情報を創作したりする可能性があります。ガードレールは、応答がソース情報を根拠としておらず (事実上不正確または新しい情報など)、ユーザーのクエリや指示と無関係である場合にハルシネーションを検出してフィルタリングするのに役立つ、コンテキストを踏まえたグラウンディングチェックをサポートします。コンテキストを踏まえたグラウンディングチェックは、RAG、要約、会話型アプリケーションのハルシネーションを検出するのに役立ちます。この場合、ソース情報はモデル応答を検証するための参照として使用できます。

自動推論チェックは、ハルシネーションによる事実の誤りを防ぎ、検証可能な正確性を実現するのに役立ちます
Amazon Bedrock ガードレールの自動推論チェック (プレビュー) は、最初で唯一の生成 AI 保護手段です。これは、論理的に正確で検証可能な推論を使用して応答が正しい理由を説明し、ハルシネーションによる事実の誤りを防ぎます。自動推論は、生成された情報を検証し、修正し、論理的に説明するための適切な数学的手法を使用してハルシネーションを軽減するのに役立ちます。これにより、出力が既知の事実と一致し、偽造されたデータや一貫性のないデータに基づいていないことが確保されます。デベロッパーは、人事ガイドラインや運用マニュアルなど、適切なソリューションスペースを定義する既存のドキュメントをアップロードすることで、自動推論ポリシーを作成できます。その後、Amazon Bedrock は独自の自動推論ポリシーを生成し、それをテストして改良する手順をユーザーに示します。生成されたコンテンツを自動推論ポリシーと照合して検証するには、ユーザーはガードレールでポリシーを有効にし、一意の Amazon リソースネーム (ARN) のリストを使用して設定する必要があります。このロジックベースのアルゴリズム検証プロセスにより、モデルによって生成された情報が既知の事実と一致し、偽造データや一貫性のないデータに基づいていないことが確保されます。これらのチェックにより、生成 AI モデルから信頼できる回答が得られ、ソフトウェアベンダーは、人事、財務、法務、コンプライアンスなどのユースケースにおけるアプリケーションの信頼性を高めることができます。

生成 AI アプリケーション内の望ましくないトピックをブロック
組織のリーダーは、適切で安全なユーザーエクスペリエンスを実現するために、生成 AI アプリケーション内のインタラクションを管理する必要性を認識しています。自社のビジネスに関連するトピックに注力し、会社の方針に沿うように、やり取りをさらにカスタマイズしたいと考えています。ガードレールは、自然言語を用いた短い説明を使用して、アプリケーションのコンテキスト内で避ける必要のある一連のトピックを定義するのに役立ちます。ガードレールは、制限されたトピックに当てはまるユーザー入力と FM 応答を検出してブロックするのに役立ちます。たとえば、バンキングアシスタントは、投資アドバイスに関連するトピックを避けるように設計できます。

責任ある AI ポリシーに基づいて有害なマルチモーダルコンテンツをフィルタリング
ガードレールは、有害なテキストおよび画像コンテンツについて、設定可能なしきい値を持つコンテンツフィルターを提供します。このセーフガードは、ヘイトスピーチ、侮辱、性的、暴力、不正行為 (犯罪行為を含む) などのトピックを含む有害なマルチモーダルコンテンツのフィルタリングと、プロンプト攻撃 (プロンプトインジェクションやジェイルブレイク) からの保護に役立ちます。コンテンツフィルターは、ユーザー入力とモデル応答の両方を自動的に評価して、有害な可能性のある望ましくないコンテンツを検出し、それらを防ぐために役立ちます。例えば、e コマースサイトでは、ヘイトスピーチや侮辱などの不適切な言葉を使わないようにオンラインアシスタントを設計できます。

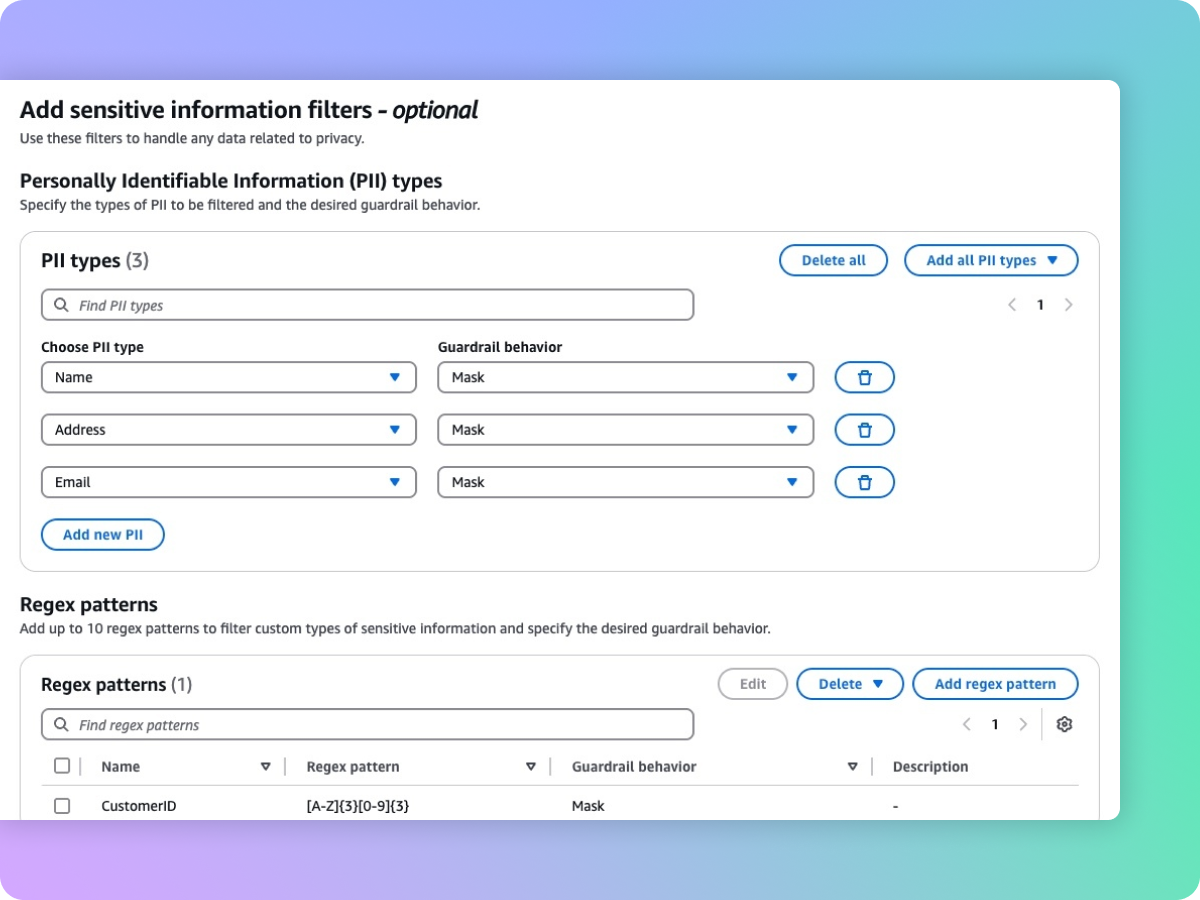
プライバシーを保護するために機密情報 (PII など) をマスキング
ガードレールは、ユーザー入力や FM 応答に含まれる個人を特定できる情報 (PII) などの機密コンテンツの検出に役立ちます。事前定義された PII のリストから選択することも、正規表現 (RegEx) を使用してカスタムの機密情報の種類を定義することもできます。ユースケースに基づいて、選択的に機密情報を含む入力を拒否したり、FM の応答でマスキングしたりできます。たとえば、コールセンターで顧客とエージェントの会話記録から要約を生成しながら、ユーザーの個人情報を編集できます。
次のステップ
今日お探しの情報は見つかりましたか?
ぜひご意見をお寄せください。ページのコンテンツ品質の向上のために役立てさせていただきます。