Amazon EMR の特徴
Amazon EMR では、必要なキャパシティーを迅速かつ簡単にプロビジョニングでき、キャパシティーを自動または手動で追加、削除できます。これは、処理要件が変動しやすい、または予測不可能な場合に非常に便利です。例えば、処理のほとんどが夜間に発生する場合、日中は 100 個のインスタンス、夜間は 500 個のインスタンスが必要になることがあります。または、短期間に大量のキャパシティーが必要な場合もあるかもしれません。Amazon EMR では、数百、数千のインスタンスをすばやくプロビジョニングし、コンピューティング要件に合わせて自動的にスケールし、ジョブが完了したら (アイドルキャパシティへの支払いを避けるために) クラスターをシャットダウンすることができます。

能力の追加と削除における主な 2 つのオプションは次のとおりです。
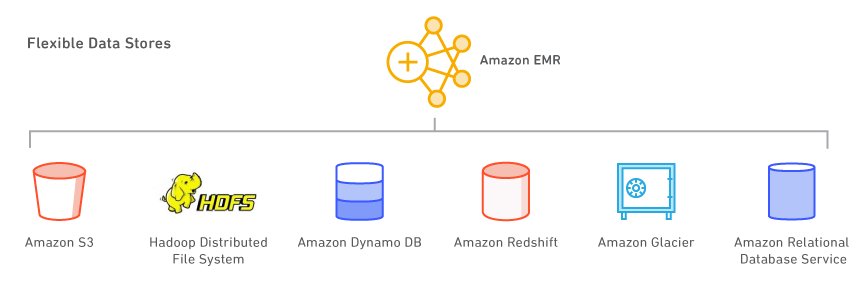
Amazon EMR では、Amazon S3、Hadoop Distributed File System(HDFS)、Amazon DynamoDB を含む複数のデータストアを利用できます。
Amazon EMR 上でのバージョンリリースにより、Apache Spark や Hadoop エコシステムのアプリケーションを含む、最新のオープンソースプロジェクトを EMR クラスタ上で簡単に選択して使用できます。ソフトウェアのインストールと設定は Amazon EMR によって行われるため、インフラストラクチャや管理タスクを気にせずに、データの価値を高めることにより多くの時間をかけることができます。

Amazon EMR では、Apache Spark、Apache Hive、Presto、Apache HBase などのパワフルで実績のある Hadoop ツールをサポートしています。データサイエンティストは、EMR を使うことで TensorFlow、Apache MXNet などの深層学習や機械学習も実行できます。また、ブートストラップアクションを使用すると、ユースケース専用のツールやライブラリを追加できます。データ分析担当者は、EMR Studio、Hue、EMR ノートブックを使用して、インタラクティブな開発、Apache Spark ジョブの作成、Apache Hive と Presto に対する SQL クエリの送信を行えます。データエンジニアは、EMR を使用して、データパイプラインの開発とデータ処理を行えます。また、Apache Hudi を使用して、増分データ管理や、レコードレベルでの挿入、更新、削除操作が必要なデータプライバシー関連のユースケースを簡素化できます。
