Barreiras de proteção do Amazon Bedrock
Implemente proteções personalizadas de acordo com os requisitos das aplicações e das políticas de IA responsáveis
Desenvolvimento de aplicações de IA responsável com as Barreiras de Proteção
As Barreiras de Proteção do Amazon Bedrock disponibilizam medidas de proteção configuráveis para auxiliar no desenvolvimento seguro de aplicações de IA generativa em grande escala. Com uma abordagem consistente e padrão usada em uma ampla variedade de modelos de base (FMs), incluindo FMs compatíveis com o Amazon Bedrock, modelos ajustados e modelos hospedados fora do Amazon Bedrock, o Guardrails oferece proteções de segurança líderes do setor:
- Uso do raciocínio automatizado para evitar erros factuais provenientes de alucinações, sendo a primeira e única proteção de IA generativa a oferecer essa funcionalidade
- Proteções de conteúdo de texto e imagem líderes do setor, ajudando os clientes a bloquear até 88% do conteúdo multimodal prejudicial
- Filtragem de mais de 75% das respostas geradas por alucinações dos modelos para casos de uso de geração aumentada via recuperação (RAG) e resumos
Remitly transforma o suporte ao cliente com velocidade e confiança usando Amazon Bedrock
KONE potencializa o serviço de campo de IA responsável com o Amazon Bedrock
Fornecimento de um nível consistente de segurança em aplicações de IA generativa
As Barreiras de Proteção correspondem à única funcionalidade de IA responsável disponibilizada por um grande provedor de nuvem que auxilia no desenvolvimento e na personalização de medidas de segurança, privacidade e veracidade para as aplicações de IA generativa em uma única solução. As Barreiras de Proteção auxiliam na avaliação das entradas dos usuários e das respostas dos modelos com base em políticas específicas para cada caso de uso, fornecendo uma camada adicional de medidas de segurança além das oferecidas nativamente pelos FMs. As Barreiras de Proteção funcionam com uma ampla variedade de modelos, incluindo FMs compatíveis com o Amazon Bedrock, modelos ajustados e modelos com hospedagem própria externa ao Amazon Bedrock. As entradas dos usuários e as saídas dos modelos podem ser avaliadas de forma independente para modelos de entidades externas e com hospedagem própria usando a API ApplyGuardrail. Além disso, as Barreiras de Proteção podem ser integradas com os Agentes do Amazon Bedrock e com as Bases de Conhecimento do Amazon Bedrock para desenvolver aplicações de IA generativa mais seguras e protegidas, alinhadas com políticas de IA responsável.

Detecte alucinações nas respostas do modelo usando verificações de fundamento contextual
É necessário que os clientes implantem aplicações de IA generativa precisas e confiáveis para preservar e aumentar a confiança dos usuários. No entanto, os modelos de base (FMs) podem gerar informações incorretas devido a alucinações, desvio das informações originais, confusão por conta de diversos dados ou invenção de novas informações. O Guardrails fornece suporte a verificações de fundamentação contextual para ajudar a detectar e filtrar alucinações, caso as respostas não estejam baseadas nas informações originais (por exemplo, informações factualmente imprecisas ou novas) e sejam irrelevantes para a consulta ou para a instrução do usuário. As verificações de fundamentação contextual podem ajudar a detectar alucinações em aplicações de RAG, resumos e conversação, em que as informações de origem podem ser usadas como referência para validar a resposta do modelo.

Ajude a evitar erros factuais causados por alucinações e obtenha precisão verificável com verificações de raciocínio automatizado
As verificações de raciocínio automatizado (versão prévia) nas Barreiras de Proteção para Amazon Bedrock são a primeira e única proteção de IA generativa que ajuda a evitar erros factuais decorrentes de alucinações ao usar um raciocínio logicamente preciso e verificável, que explica a razão pela qual as respostas estão corretas. O raciocínio automatizado ajuda a mitigar as alucinações ao usar técnicas matemáticas confiáveis para verificar, corrigir e explicar logicamente as informações geradas, garantindo que os resultados estejam alinhados com fatos conhecidos e não sejam baseados em dados fabricados ou inconsistentes. Os desenvolvedores podem criar uma política de raciocínio automatizado ao fazer o upload de um documento existente que defina o espaço de soluções adequado, como uma diretriz de RH ou um manual operacional. Em seguida, o Amazon Bedrock cria uma política exclusiva de raciocínio automatizado e orienta os usuários durante os testes e o aprimoramento da política. Para validar o conteúdo gerado de acordo com uma política de raciocínio automatizado, os usuários precisam habilitar a política nas Barreiras de Proteção e configurá-la com uma lista de nomes dos recursos da Amazon (ARNs) exclusivos. Esse processo de verificação algorítmica baseado em lógica garante que as informações geradas por um modelo estejam alinhadas com fatos conhecidos e não sejam baseadas em dados fabricados ou inconsistentes. Essas verificações fornecem respostas comprovadamente verdadeiras de modelos de IA generativa, possibilitando que os fornecedores de software aumentem a confiabilidade das aplicações para casos de uso em setores de RH, finanças, jurídico, conformidade, entre outros.

Bloqueio de tópicos indesejáveis em aplicações de IA generativa
Os líderes organizacionais reconhecem a necessidade de gerenciar as interações nas aplicações de IA generativa para proporcionar uma experiência de usuário relevante e segura. Eles desejam personalizar as interações de forma mais aprofundada, garantindo que permaneçam concentradas em tópicos relevantes para os negócios e em conformidade com as políticas da empresa. Com uma breve descrição em linguagem natural, as Barreiras de Proteção auxiliam na definição de um conjunto de tópicos a serem evitados no âmbito de sua aplicação. As Barreiras de Proteção auxiliam na detecção e no bloqueio de entradas de usuários e respostas de FM que pertencem aos tópicos restritos. Por exemplo, um assistente de banco pode ser projetado para evitar tópicos relacionados à consultoria de investimentos.

Filtre conteúdo nocivo multimodal com base em políticas de IA responsáveis
As Barreiras de Proteção fornecem filtros de conteúdo com limites configuráveis para conteúdo tóxico de texto e imagem. A proteção ajuda a filtrar conteúdo multimodal prejudicial contendo tópicos como discurso de ódio, insultos, sexo, violência e má conduta (incluindo atividades criminosas) e ajuda a proteger contra ataques de prompt (injeção de prompt e jailbreak). Os filtros de conteúdo avaliam automaticamente a entrada do usuário e as respostas do modelo para detectar e ajudar a evitar textos e/ou imagens indesejáveis e potencialmente prejudiciais. Por exemplo, um site de comércio eletrônico pode criar um assistente on-line para evitar o uso de linguagem imprópria, como discurso de ódio ou insultos.

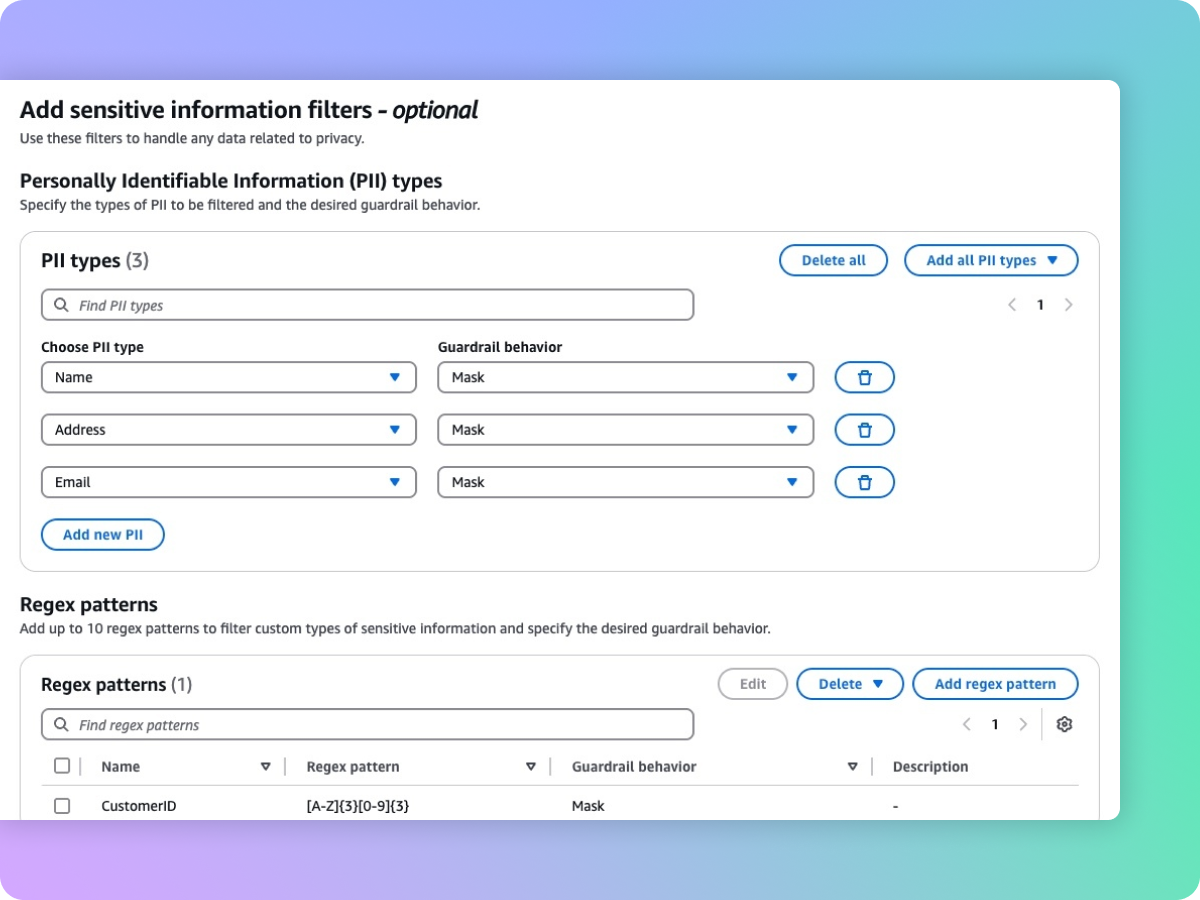
Ocultação de informações confidenciais, como PII, para proteger a privacidade
As Barreiras de Proteção auxiliam na detecção de conteúdo confidencial, como informações de identificação pessoal (PII), em entradas de usuários e respostas de FMs. É possível selecionar a partir de uma lista de PII definidas previamente ou definir um tipo personalizado de informações confidenciais usando expressões regulares (RegEx). Com base no caso de uso, você pode rejeitar seletivamente as entradas que contêm informações confidenciais ou ocultá-las nas respostas dos FMs. Por exemplo, você pode editar as informações pessoais dos usuários enquanto gera resumos das transcrições de conversas com clientes e atendentes em uma central de atendimento.
Próximas etapas
Você encontrou o que estava procurando hoje?
Informe-nos para que possamos melhorar a qualidade do conteúdo em nossas páginas.